Pavan Chhatpar






I co-architected Honeywell's Agentic AI platform, enabling teams across the organization to build and deploy production-ready AI agents with capabilities including multi-tenancy, scalable orchestration, retrieval over large vector databases, responsible AI guardrails, observability, and continuous feedback. The platform also powers private, air-gapped AI deployments through optimized and fine-tuned open-source LLMs.
My experience spans the entire machine learning lifecycle—from training multimodal transformer models and building real-time learning systems to optimizing high-performance inference using Kubernetes, vLLM, KServe, ONNX, and model quantization. I enjoy solving systems-level challenges that make AI reliable, scalable, and accessible in production.
I hold an M.S. in Computer Science with a specialization in Natural Language Processing, giving me a strong foundation in generative modeling alongside deep software engineering expertise. I enjoy bridging AI research with production systems and contributing to open-source technologies that advance the AI ecosystem.
Skills
Areas of Interest

NLP
I dive into various NLP techniques, and focus on Natural Language Generation. I have experience using transfer learning for fine-tuning task specific deep neural nets.

Machine Learning
ML is way more than being able to use packages. I code the algorithms to understand its nuances and how the packages get to an efficient implementation. I find that the math becomes easier along the way of implementing it.

Competitive Coding
Every now and then I find myself spending hours improving efficiency of my code and its always a fun exercise. The end result of seeing the execution time reduce by a very high rate brings a feeling of satisfaction.

Containerization
I try to incorporate, for dev and prod environments, containerization tools like Docker, conda, and venv just so that I don't have to scream "But it worked on my laptop!" in the end.
Projects
RAG with Open LLMs and Vector DB
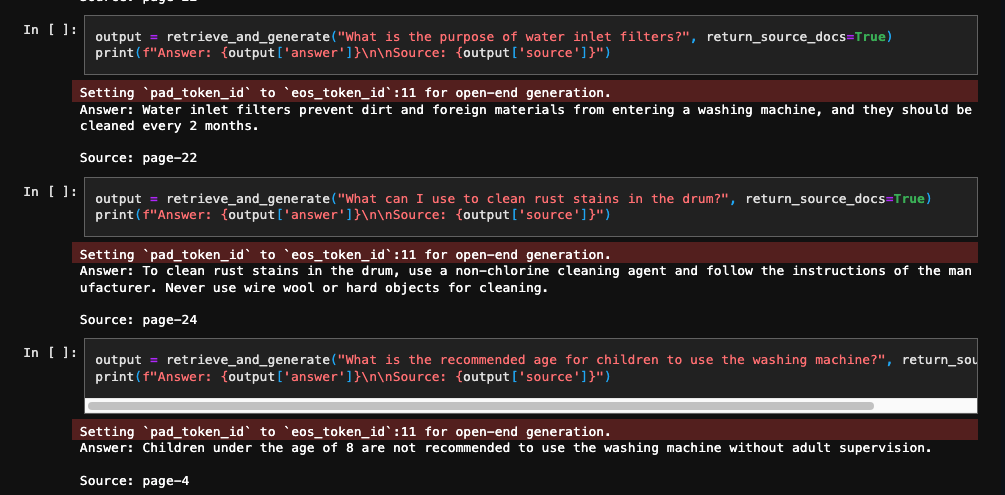
A POC that shows using RAG to get answers from a User Manual. It was implemented using a Vector Index from FAISS and Falcon-40B-Instruct (an Open-Source LLM), chained together with the help of LangChain. To add confidence in replies, the answers also cite their sources for reference. This project demonstrates the efficacy of prompt engineering and tuning generation parameters to get useful answers from Open LLMs.
Endodontic case difficulty and referral decisions
An interdisciplinary research work where ML was used to automate the referral decision of endodontic cases, which was deployed as a mobile app to use at a busy Nair Dental Hospital, Mumbai. Published in Clinical Oral Investigations, Aug. 2019
Question generation using Copy Mechanism
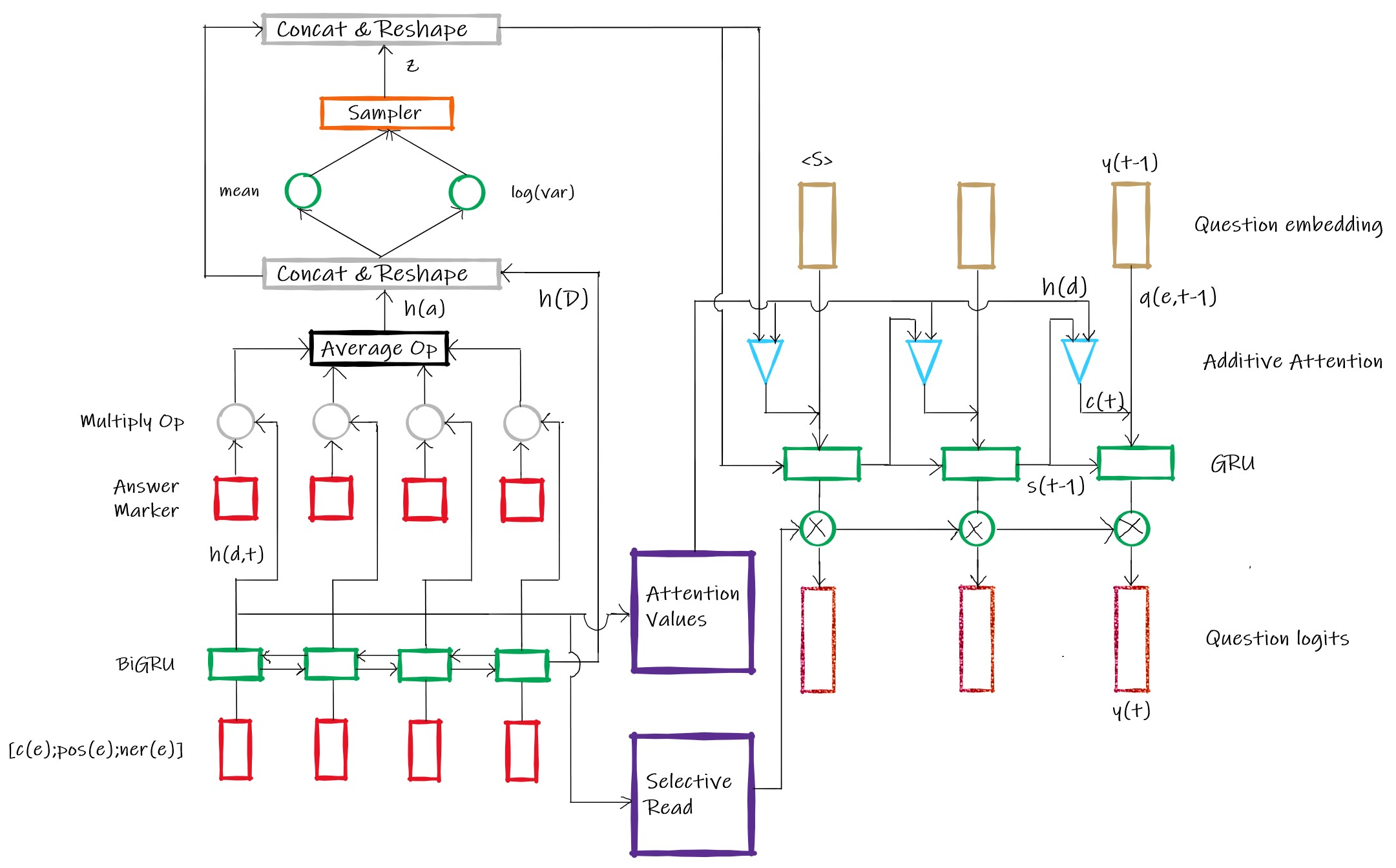
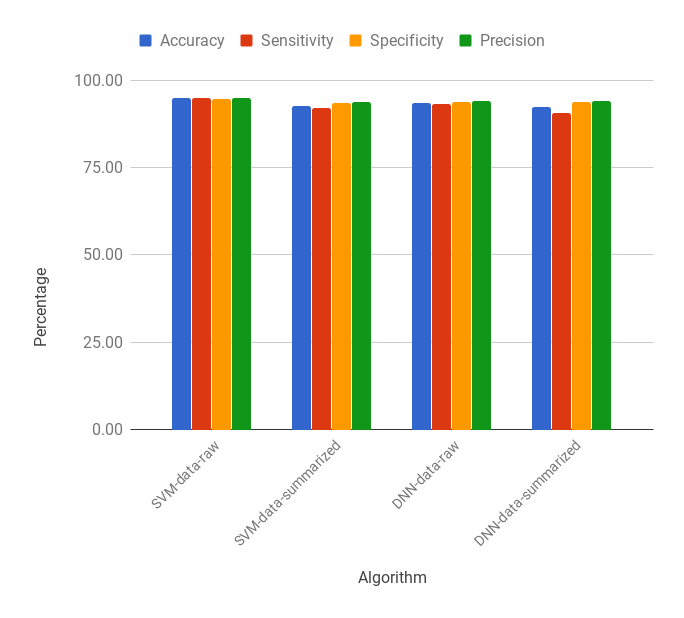
Used SQuAD 1.1 to train a seq2seq model that employs copy mechanism to generate questions given a pair of context and answer. All code for the model architecture was written using TensorFlow 2.2. Published copynet-tf which can be trained for any seq2seq task that would benefit from copy mechanism. Questions generated could predict answers with 18% lesser F1 score compared to original questions.
Discourse based sentence splitter
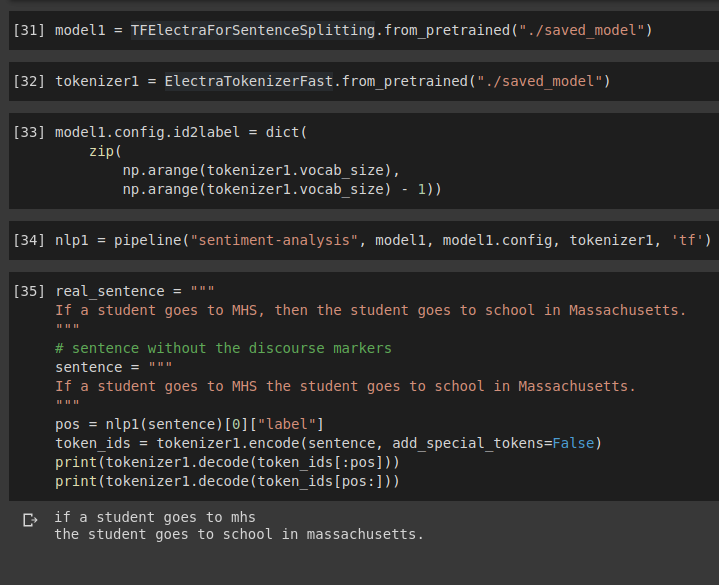
In the absence of a discourse marker, splitting a sentence at the point of discourse is tricky and such discourse based splitting is quite useful in many NLP tasks. I fine tuned ELECTRA with an appropriate head using transformers library to achieve 91.8% test accuracy in 2 epochs.
Exploring generalizability of AttnGAN

Explored the generalizability of an attention-driven GAN model by trying latent space interpolations and understanding the role of the latent vector. The model was also tightly dependent on a particular sentence syntax. It was for an individual project work of CS 7180
Vehicular Traffic Abatement
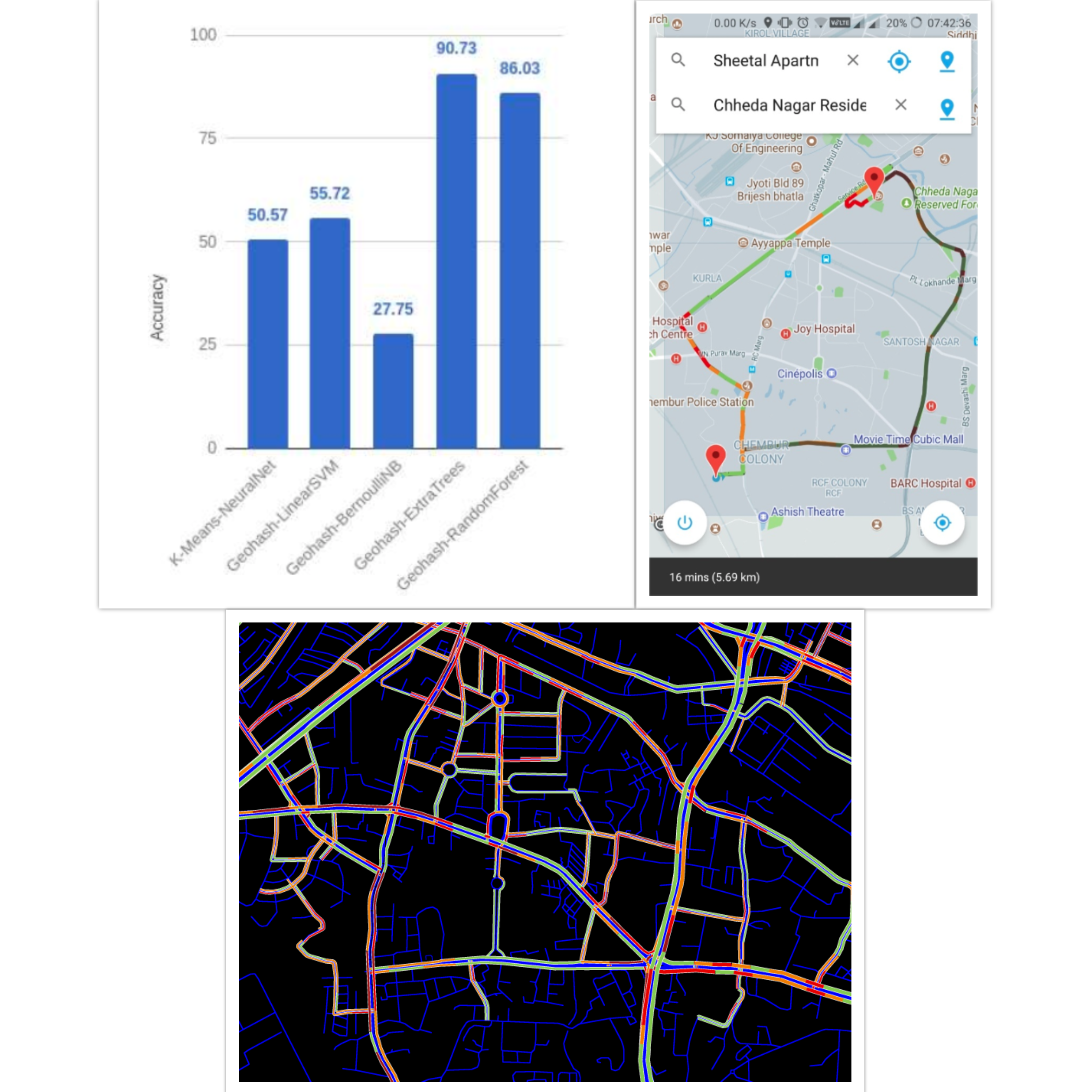
Employed various ensemble model techniques to make a tri-class predictor of traffic density in a given location at a given time using over a half a year of crawled data. It was my team's final year undergrad project which was published in ICSCET, an IEEE conference and IJRASET in 2018
ML Algorithms
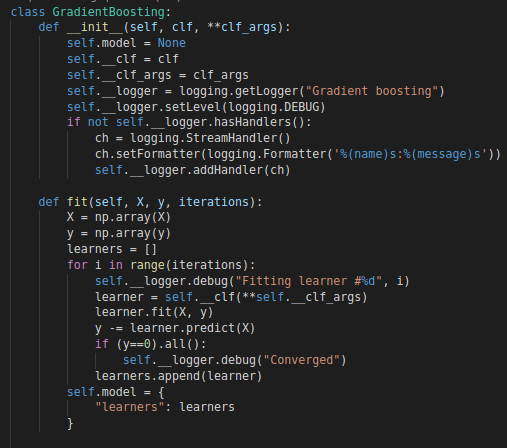
A playground repository for various ML algorithms which I implemented as I was learning about them. They may not be optimized like sklearn but it laid a very strong base about my understanding of how things work under the hood.
bunk-manager
An Android app for managing bunks from tracking attendance to even planning bunks
csv-to-sql-converter
A shell script that converts a csv file (Excel Sheet) to an SQL file that can be imported in a MySQL database
wav-steg-py
A python script to hide information over an audio file in .wav format
cooja-simulation
RPL network simulation using 6lowpan for a hospital, with security services added
VSM
Web Technologies mini project, Virtual Stock Market
packet-sniffer
A Packet Sniffer app made using Python for Linux
Page template forked from evanca